Desbloqueando Perspectivas de Negocio: Cómo DeepScope Transforma Datos en Estrategias Accionables
Imagina intentar entender una ciudad mirando cada ladrillo de cada edificio. Imposible, ¿verdad? Exactamente así es como las empresas luchan con los datos: ahogándose en detalles, perdiendo la visión global. En el panorama digital actual, las organizaciones recopilan volúmenes sin precedentes de información, pero sin las herramientas adecuadas para interpretarla, estos datos siguen siendo un recurso sin explotar en lugar de un activo estratégico.
El Desafío de la Complejidad de Datos
La mayoría de las empresas recopilan grandes cantidades de datos en múltiples dominios: interacciones con clientes, registros de ventas, detalles de productos y comportamientos de usuarios. Pero el problema es que los datos no son solo grandes. Son masivamente complejos y multidimensionales. Un solo perfil de cliente puede contener docenas de atributos: edad, historial de compras, patrones de navegación, información demográfica, preferencias de productos, interacciones de servicio e innumerables dimensiones más. Cuando se multiplica por miles o millones de clientes, esta complejidad se vuelve abrumadora. Los métodos de análisis tradicionales simplemente no pueden procesar estas intrincadas relaciones de manera efectiva, lo que lleva a percepciones superficiales o parálisis analítica completa.
Las Limitaciones Fundamentales del Análisis Clásico de Datos
Los enfoques tradicionales de análisis de datos tratan los datos de alta dimensionalidad como un espacio simple y lineal, representando de manera fundamentalmente errónea la estructura intrínseca de conjuntos de datos complejos. Como argumentaron convincentemente Tenenbaum et al. (2000) en su artículo seminal en Science, “la hipótesis de variedad subyacente sugiere que los datos de alta dimensionalidad a menudo se encuentran cerca de una variedad de dimensionalidad mucho menor” [1].
Considera un conjunto de datos de retail con miles de registros de transacciones, cada uno conteniendo cientos de atributos. Los enfoques clásicos como la regresión lineal o el clustering básico pueden identificar segmentos amplios de clientes, pero pierden las relaciones no lineales matizadas que impulsan las decisiones de compra.
El Poder de las Variedades: Entendiendo la Estructura Intrínseca de los Datos
Nuestro enfoque está fundamentalmente construido sobre el concepto de variedades (manifolds): estructuras de baja dimensionalidad incrustadas dentro de espacios de alta dimensionalidad. En datos del mundo real, a pesar de tener cientos de variables, las variaciones significativas reales a menudo se encuentran en una variedad de dimensionalidad mucho menor. Considera el comportamiento del cliente: aunque podemos rastrear miles de puntos de interacción, los clientes típicamente siguen un número limitado de patrones de comportamiento. Estos patrones intrínsecos forman una variedad en el espacio de datos de alta dimensionalidad.
A diferencia de muchos métodos analíticos que comienzan con características brutas, nuestro sistema parte de distancias por pares entre puntos de datos. Este enfoque centrado en distancias conecta nuestro trabajo con los métodos kernel en aprendizaje automático, que transforman relaciones complejas y no lineales en formas más manejables. Al definir la similitud a través de diversas métricas de distancia en lugar de características brutas, podemos detectar patrones que serían invisibles en el espacio de características original.
La brillantez de este enfoque radica en su flexibilidad. Al operar sobre distancias en lugar de características brutas, podemos analizar la misma variedad subyacente desde múltiples perspectivas, aplicando diferentes métricas de distancia (Levenshtein, similitud coseno) o modelos de embedding (MiniLM, MPNet) para iluminar diferentes aspectos de la estructura de los datos. Esto nos permite triangular una comprensión más completa de la realidad subyacente, separando el ruido de la señal con mayor certeza.
Fundamento Técnico: De Distancias a Perspectivas Descubribles
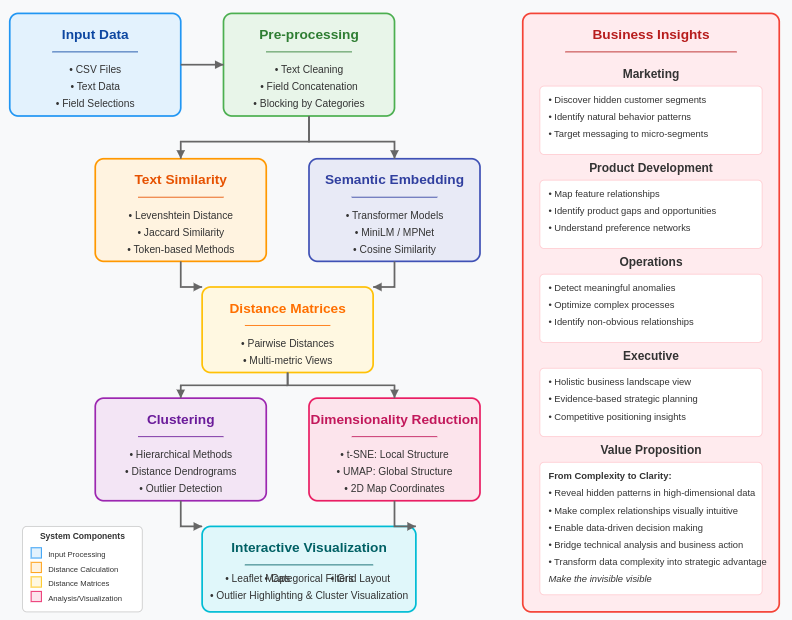
Nuestro pipeline implementa un enfoque sofisticado de aprendizaje de variedades basado en distancias que se nutre tanto del análisis topológico de datos como de la teoría de embedding espectral. El proceso comienza calculando matrices de distancia: representaciones matemáticas de cómo cada punto de datos se relaciona con todos los demás puntos en tu conjunto de datos. Estas distancias forman un mapeo completo de la estructura relacional de tus datos.
El enfoque multi-métrica es crucial. Al calcular distancias usando tanto métodos léxicos (Levenshtein, Jaccard) como métodos semánticos (embeddings basados en transformers), capturamos tanto las relaciones a nivel superficial como las contextuales profundas. Cada métrica de distancia proporciona un lente diferente hacia la estructura de los datos, revelando aspectos de la variedad que otras métricas podrían pasar por alto. Esto es particularmente valioso en contextos empresariales, donde las relaciones entre entidades (clientes, productos, comportamientos) son complejas y multifacéticas.
Cálculos de Distancia Multifacéticos: Un Enfoque Holístico
Nuestra metodología aprovecha múltiples métricas de distancia para crear una vista completa de los datos:
Distancia de Levenshtein:
- Captura disimilitudes basadas en edición
- Ideal para datos textuales o categóricos
- Mide el número mínimo de ediciones de un solo carácter necesarias para transformar una cadena en otra
Distancia Coseno:
- Utiliza modelos de embedding avanzados
- Captura similitudes semánticas
- Representa la distancia angular en espacios vectoriales de alta dimensión
Métricas Basadas en Tokens:
- Descompone los datos en componentes fundamentales
- Proporciona mediciones de similitud granulares
- Adaptable a varios tipos de datos y dominios
Estas diferentes métricas implementadas en nuestro repositorio trabajan juntas para proporcionar una vista completa de la estructura de los datos, asegurando que tanto las similitudes a nivel superficial como las relaciones semánticas más profundas sean capturadas.
Diversidad de Embeddings: Un Marco Analítico Multi-Perspectiva
Los diferentes modelos de embedding en nuestra implementación capturan aspectos únicos de los datos:
Sentence Transformers:
- Nuestro repositorio usa MiniLM para crear representaciones semánticas de texto
- Preserva el significado contextual mientras es computacionalmente eficiente
Al ofrecer estas opciones de embedding en nuestro código, habilitamos un análisis robusto y multi-perspectiva que trasciende las limitaciones de un solo modelo.
Detección de Valores Atípicos a Través del Análisis de Variedades
Uno de los aspectos más poderosos de nuestro enfoque basado en variedades es la detección superior de valores atípicos. Los métodos tradicionales de detección de valores atípicos a menudo fallan porque dependen de medidas estadísticas simplistas en el espacio original de alta dimensionalidad. Nuestro enfoque examina cómo los puntos se relacionan con la estructura de variedad descubierta, identificando verdaderas anomalías: puntos que se desvían significativamente de los patrones subyacentes en lugar de simplemente tener valores extremos.
Esta detección de valores atípicos consciente de variedades proporciona un valor empresarial extraordinario. En analítica de clientes, identifica patrones de comportamiento verdaderamente inusuales en lugar de meros valores atípicos estadísticos. En datos de productos, revela combinaciones genuinamente innovadoras en lugar de simplemente características poco comunes. En contextos operativos, resalta desviaciones de procesos que representan irregularidades reales en lugar de variaciones benignas.
Al aprovechar los algoritmos de isolation forest y factor de atipicidad local contra nuestra representación de variedad tal como se implementa en nuestro repositorio de código, logramos un sistema de detección de anomalías robusto y multi-perspectiva que separa las desviaciones significativas del ruido. Esta vista multi-angular asegura que los valores atípicos identificados representen oportunidades o preocupaciones empresariales genuinas en lugar de artefactos estadísticos.
Estrategias Avanzadas de Detección de Valores Atípicos
Nuestro código implementa múltiples enfoques complementarios para la detección de valores atípicos:
Método Z-score:
- Identifica desviaciones estadísticamente significativas
- Enfoque de referencia para el filtrado inicial
Isolation Forest:
- Reconoce anomalías a través del aislamiento computacional
- Implementado en nuestro módulo de detección de valores atípicos
Factor de Atipicidad Local:
- Captura variaciones de densidad local
- Identifica anomalías dependientes del contexto
La perspectiva clave, como demostró la investigación revolucionaria de t-SNE de Van Der Maaten y Hinton [3], es que los valores atípicos a menudo revelan las características estructurales más interesantes de un conjunto de datos.
El Proceso Analítico Avanzado
Nuestra implementación sigue un pipeline sofisticado que asegura resultados precisos y significativos. Inicialmente, procesamos los datos de entrada a través de pasos de limpieza y normalización para garantizar la consistencia. El sistema luego calcula distancias por pares entre puntos de datos usando múltiples métricas, construyendo una vista completa de la estructura relacional de los datos.
Para cada métrica de distancia, nuestro código crea una matriz de distancia separada, proporcionando múltiples perspectivas sobre los mismos datos subyacentes. Estas vistas complementarias nos permiten identificar patrones robustos que persisten a través de diferentes enfoques de medición, distinguiendo la estructura genuina de los artefactos de medición. Este enfoque multi-métrica es particularmente valioso para datos empresariales ricos en texto, donde diferentes conceptos de similitud (coincidencia exacta, significado semántico, superposición de tokens) pueden revelar diferentes aspectos de las relaciones subyacentes.
Cuando se trabaja con campos de bloqueo categóricos (como segmentos de clientes, categorías de productos o regiones geográficas), nuestro sistema crea visualizaciones separadas para cada bloque mientras mantiene un marco de análisis unificado. El diseño de cuadrícula resultante permite tanto el examen enfocado dentro de categorías como el análisis comparativo entre ellas, proporcionando perspectivas en múltiples niveles de categorización empresarial.
Impacto Real en los Negocios: Más Allá de Gráficos Bonitos
Esta tecnología no se trata de crear gráficos estéticamente agradables, sino de transformar las capacidades de toma de decisiones en múltiples funciones empresariales. En segmentación de clientes, en lugar de luchar con cientos de variables por separado, nuestro enfoque revela agrupaciones naturales de clientes basadas en patrones de comportamiento complejos que los métodos tradicionales pasarían por alto. Estos segmentos emergentes a menudo trascienden las categorizaciones demográficas convencionales, ofreciendo mayor poder predictivo para iniciativas de marketing y desarrollo de productos.
Para los equipos de gestión de productos, nuestro enfoque de aprendizaje de variedades mapea cómo diferentes características y atributos se relacionan entre sí en todo tu portafolio. Esta vista integral descubre redes complejas de preferencias de clientes que no serían visibles al examinar productos individualmente. El resultado es la identificación de oportunidades innovadoras de productos que existen en espacios actualmente desocupados dentro de tu panorama de mercado.
La optimización de la cadena de suministro se beneficia de la identificación de patrones ocultos en datos logísticos, revelando relaciones no obvias entre factores operativos aparentemente no relacionados. Al visualizar estas conexiones en la variedad, las empresas pueden identificar cuellos de botella e ineficiencias que permanecen invisibles en los dashboards y reportes convencionales.
Reducción de Dimensionalidad: El Paso Final de Visualización
Como paso final en nuestro pipeline, empleamos técnicas de reducción de dimensionalidad para crear visualizaciones significativas de las estructuras complejas de variedades que hemos descubierto. Nuestra implementación ofrece dos opciones poderosas:
t-SNE (t-Distributed Stochastic Neighbor Embedding):
- Preserva la estructura local con alta fidelidad
- Excelente para identificar clusters ajustados
- Revela patrones de grano fino
UMAP (Uniform Manifold Approximation and Projection):
- Mantiene tanto la estructura local como global
- Cómputo más rápido para conjuntos de datos grandes
- Más estable a través de diferentes parámetros
Estas técnicas forman la capa final de visualización de nuestro sistema, traduciendo las complejas relaciones de distancia y estructuras de variedades en representaciones visuales comprensibles que los usuarios de negocio pueden explorar y entender.
Visualización: Haciendo los Datos Tangibles
La salida de nuestro pipeline de aprendizaje de variedades se renderiza a través de mapas interactivos Leaflet, creando una representación espacial intuitiva de tu panorama de datos. Este sistema de visualización incluye codificación de colores sofisticada basada en variables categóricas o numéricas, permitiéndote identificar instantáneamente patrones a través de múltiples dimensiones empresariales simultáneamente. Cuando se trabaja con datos segmentados por campos categóricos como tipos de productos, segmentos de clientes o períodos de tiempo, nuestro sistema de cuadrícula organiza estos bloques en un diseño cohesivo, habilitando tanto la exploración detallada dentro de categorías como el análisis comparativo entre ellas.
La visualización no solo muestra la reducción de dimensionalidad; mantiene conexiones con todas las métricas de distancia calculadas, espacios de embedding y características originales. Esto permite a los usuarios alternar entre diferentes perspectivas sobre la misma variedad subyacente, obteniendo una comprensión más completa de la estructura de los datos. La codificación por colores de los puntos basada en diferentes variables ilumina cómo varios factores empresariales se relacionan con los patrones descubiertos, mientras que el filtrado interactivo habilita la prueba de hipótesis y la exploración de escenarios en tiempo real.
Realización del Valor Empresarial
El impacto empresarial inmediato proviene de la transformación de una complejidad abrumadora en perspectivas claras y accionables. Los equipos de marketing pueden dirigirse a segmentos de clientes previamente invisibles con mensajes personalizados. Los equipos de producto pueden identificar brechas en las ofertas actuales y oportunidades de innovación. Las operaciones pueden detectar ineficiencias y optimizar flujos de trabajo basados en patrones recién visibles. Los equipos ejecutivos obtienen una vista holística del panorama empresarial, permitiendo una planificación estratégica más efectiva y posicionamiento competitivo.
La reducción de dimensionalidad no se trata de simplificar datos, sino de amplificar la comprensión. Al transformar la complejidad en claridad a través de técnicas sofisticadas de aprendizaje de variedades, este enfoque permite a las empresas ver el bosque y los árboles simultáneamente, haciendo conexiones que impulsan la ventaja competitiva en un entorno empresarial cada vez más rico en datos.
A través de nuestro enfoque técnico integral, combinando aprendizaje de variedades basado en distancias, embeddings de transformers, reducción de dimensionalidad t-SNE y UMAP, visualizaciones interactivas Leaflet, sistemas de cuadrícula categórica y detección de valores atípicos consciente de variedades, traducimos la complejidad de tus datos en una narrativa clara y accionable que impulsa el valor empresarial en cada departamento.
Repositorio GitHub
https://github.com/Tailoredia/deepscope/tree/develop
Referencias
[1] Tenenbaum, J. B., de Silva, V., & Langford, J. C. (2000). A global geometric framework for nonlinear dimensionality reduction. Science, 290(5500), 2319-2323.
[2] Belkin, M., & Niyogi, P. (2003). Laplacian eigenmaps and spectral techniques for embedding and clustering. Advances in Neural Information Processing Systems, 14.
[3] Van Der Maaten, L., & Hinton, G. (2008). Visualizing data using t-SNE. Journal of Machine Learning Research, 9(Nov), 2579-2605.
[4] McInnes, L., Healy, J., & Melville, J. (2018). UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction. ArXiv e-prints.
[5] Liu, F. T., Ting, K. M., & Zhou, Z. H. (2008). Isolation forest. In 2008 Eighth IEEE International Conference on Data Mining (pp. 413-422).
