Sbloccare Insight di Business: Come DeepScope Trasforma i Dati Grezzi in Strategie Attuabili
Immagina di cercare di capire una città guardando ogni singolo mattone di ogni edificio. Impossibile, vero? È esattamente così che le aziende lottano con i dati: annegando nei dettagli, perdendo il quadro generale. Nel panorama digitale odierno, le organizzazioni raccolgono volumi senza precedenti di informazioni, ma senza gli strumenti giusti per interpretarle, questi dati rimangono una risorsa inesplorata piuttosto che un asset strategico.
La Sfida della Complessità dei Dati
La maggior parte delle aziende raccoglie grandi quantità di dati in molteplici domini: interazioni con i clienti, registri di vendita, dettagli dei prodotti e comportamenti degli utenti. Ma ecco il problema: i dati non sono solo grandi. Sono enormemente complessi e multidimensionali. Un singolo profilo cliente potrebbe contenere decine di attributi: età, storico acquisti, modelli di navigazione, informazioni demografiche, preferenze di prodotto, interazioni con il servizio e innumerevoli altre dimensioni. Quando moltiplicati per migliaia o milioni di clienti, questa complessità diventa travolgente. I metodi di analisi tradizionali semplicemente non possono elaborare queste intricate relazioni in modo efficace, portando a insight superficiali o completa paralisi analitica.
Le Limitazioni Fondamentali dell’Analisi Classica dei Dati
Gli approcci tradizionali all’analisi dei dati trattano i dati ad alta dimensionalità come uno spazio semplice e lineare, rappresentando in modo fondamentalmente errato la struttura intrinseca di dataset complessi. Come hanno sostenuto in modo convincente Tenenbaum et al. (2000) nel loro articolo seminale su Science, “l’ipotesi della varietà sottostante suggerisce che i dati ad alta dimensionalità spesso giacciono vicino a una varietà di dimensionalità molto inferiore” [1].
Considera un dataset retail con migliaia di registri di transazioni, ciascuno contenente centinaia di attributi. Gli approcci classici come la regressione lineare o il clustering di base possono identificare ampi segmenti di clienti, ma perdono le relazioni non lineari sfumate che guidano le decisioni di acquisto.
Il Potere delle Varietà: Comprendere la Struttura Intrinseca dei Dati
Il nostro approccio è fondamentalmente costruito sul concetto di varietà (manifold): strutture a bassa dimensionalità incorporate in spazi ad alta dimensionalità. Nei dati del mondo reale, nonostante abbiano centinaia di variabili, le variazioni significative effettive spesso giacciono su una varietà di dimensionalità molto inferiore. Considera il comportamento del cliente: sebbene possiamo tracciare migliaia di punti di interazione, i clienti tipicamente seguono un numero limitato di modelli comportamentali. Questi modelli intrinseci formano una varietà nello spazio dati ad alta dimensionalità.
A differenza di molti metodi analitici che partono dalle caratteristiche grezze, il nostro sistema parte dalle distanze a coppie tra i punti dati. Questo approccio centrato sulle distanze collega il nostro lavoro ai metodi kernel nel machine learning, che trasformano relazioni complesse e non lineari in forme più gestibili. Definendo la similarità attraverso diverse metriche di distanza piuttosto che caratteristiche grezze, possiamo rilevare modelli che sarebbero invisibili nello spazio delle caratteristiche originale.
La brillantezza di questo approccio risiede nella sua flessibilità. Operando sulle distanze piuttosto che sulle caratteristiche grezze, possiamo analizzare la stessa varietà sottostante da molteplici prospettive, applicando diverse metriche di distanza (Levenshtein, similarità coseno) o modelli di embedding (MiniLM, MPNet) per illuminare diversi aspetti della struttura dei dati. Questo ci permette di triangolare una comprensione più completa della realtà sottostante, separando il rumore dal segnale con maggiore certezza.
Fondamento Tecnico: Dalle Distanze agli Insight Scopribili
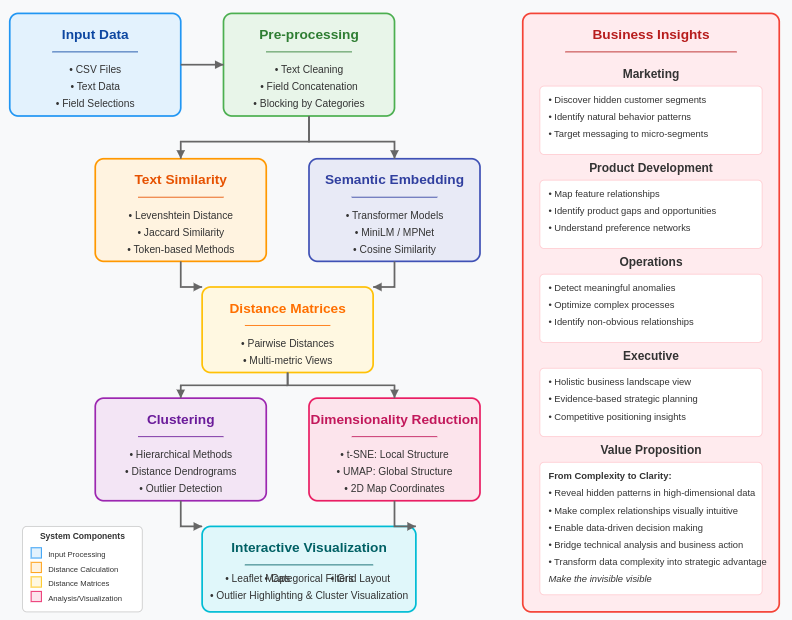
La nostra pipeline implementa un sofisticato approccio di apprendimento delle varietà basato sulle distanze che attinge sia dall’analisi topologica dei dati che dalla teoria dell’embedding spettrale. Il processo inizia calcolando matrici di distanza: rappresentazioni matematiche di come ogni punto dati si relaziona a ogni altro punto nel dataset. Queste distanze formano una mappatura completa della struttura relazionale dei dati.
L’approccio multi-metrica è cruciale. Calcolando le distanze usando sia metodi lessicali (Levenshtein, Jaccard) che metodi semantici (embedding basati su transformer), catturiamo sia le relazioni a livello superficiale che quelle contestuali profonde. Ogni metrica di distanza fornisce una lente diversa nella struttura dei dati, rivelando aspetti della varietà che altre metriche potrebbero mancare. Questo è particolarmente prezioso nei contesti aziendali, dove le relazioni tra entità (clienti, prodotti, comportamenti) sono complesse e sfaccettate.
Calcoli di Distanza Multisfaccettati: Un Approccio Olistico
La nostra metodologia sfrutta molteplici metriche di distanza per creare una vista completa dei dati:
Distanza di Levenshtein:
- Cattura dissimilarità basate sull’editing
- Ideale per dati testuali o categorici
- Misura il numero minimo di modifiche a singolo carattere necessarie per trasformare una stringa in un’altra
Distanza Coseno:
- Utilizza modelli di embedding avanzati
- Cattura similarità semantiche
- Rappresenta la distanza angolare in spazi vettoriali ad alta dimensione
Metriche Basate su Token:
- Scompone i dati in componenti fondamentali
- Fornisce misurazioni di similarità granulari
- Adattabile a vari tipi di dati e domini
Queste diverse metriche implementate nel nostro repository lavorano insieme per fornire una vista completa della struttura dei dati, assicurando che sia le similarità a livello superficiale che le relazioni semantiche più profonde vengano catturate.
Diversità degli Embedding: Un Framework Analitico Multi-Prospettiva
I diversi modelli di embedding nella nostra implementazione catturano aspetti unici dei dati:
Sentence Transformers:
- Il nostro repository usa MiniLM per creare rappresentazioni semantiche del testo
- Preserva il significato contestuale essendo computazionalmente efficiente
Offrendo queste opzioni di embedding nel nostro codice, abilitiamo un’analisi robusta e multi-prospettiva che trascende le limitazioni di un singolo modello.
Rilevamento degli Outlier Attraverso l’Analisi delle Varietà
Uno degli aspetti più potenti del nostro approccio basato sulle varietà è il rilevamento superiore degli outlier. I metodi tradizionali di rilevamento degli outlier spesso falliscono perché si basano su misure statistiche semplicistiche nello spazio originale ad alta dimensionalità. Il nostro approccio esamina come i punti si relazionano alla struttura della varietà scoperta, identificando vere anomalie: punti che deviano significativamente dai modelli sottostanti piuttosto che avere semplicemente valori estremi.
Questo rilevamento degli outlier consapevole delle varietà fornisce un valore aziendale straordinario. Nell’analisi dei clienti, identifica modelli comportamentali veramente insoliti piuttosto che semplici outlier statistici. Nei dati dei prodotti, rivela combinazioni genuinamente innovative piuttosto che caratteristiche semplicemente non comuni. Nei contesti operativi, evidenzia deviazioni di processo che rappresentano irregolarità reali piuttosto che variazioni benigne.
Sfruttando gli algoritmi di isolation forest e fattore di outlier locale contro la nostra rappresentazione delle varietà come implementato nel nostro repository di codice, otteniamo un sistema di rilevamento anomalie robusto e multi-prospettiva che separa le deviazioni significative dal rumore. Questa vista multi-angolare assicura che gli outlier identificati rappresentino genuine opportunità o preoccupazioni aziendali piuttosto che artefatti statistici.
Strategie Avanzate di Rilevamento degli Outlier
Il nostro codice implementa molteplici approcci complementari al rilevamento degli outlier:
Metodo Z-score:
- Identifica deviazioni statisticamente significative
- Approccio di base per lo screening iniziale
Isolation Forest:
- Riconosce anomalie attraverso l’isolamento computazionale
- Implementato nel nostro modulo di rilevamento degli outlier
Fattore di Outlier Locale:
- Cattura variazioni di densità locale
- Identifica anomalie dipendenti dal contesto
L’insight chiave, come dimostrato dalla ricerca rivoluzionaria di Van Der Maaten e Hinton su t-SNE [3], è che gli outlier spesso rivelano le caratteristiche strutturali più interessanti di un dataset.
Il Processo Analitico Avanzato
La nostra implementazione segue una pipeline sofisticata che assicura risultati accurati e significativi. Inizialmente, elaboriamo i dati di input attraverso fasi di pulizia e normalizzazione per garantire la coerenza. Il sistema quindi calcola distanze a coppie tra i punti dati usando molteplici metriche, costruendo una vista completa della struttura relazionale dei dati.
Per ogni metrica di distanza, il nostro codice crea una matrice di distanza separata, fornendo molteplici prospettive sugli stessi dati sottostanti. Queste viste complementari ci permettono di identificare modelli robusti che persistono attraverso diversi approcci di misurazione, distinguendo la struttura genuina dagli artefatti di misurazione. Questo approccio multi-metrica è particolarmente prezioso per dati aziendali ricchi di testo, dove diversi concetti di similarità (corrispondenza esatta, significato semantico, sovrapposizione di token) possono rivelare diversi aspetti delle relazioni sottostanti.
Quando si lavora con campi di blocco categorici (come segmenti di clienti, categorie di prodotti o regioni geografiche), il nostro sistema crea visualizzazioni separate per ogni blocco mantenendo un framework di analisi unificato. Il layout a griglia risultante consente sia l’esame focalizzato all’interno delle categorie che l’analisi comparativa tra di esse, fornendo insight a molteplici livelli di categorizzazione aziendale.
Impatto Reale sul Business: Oltre i Grafici Belli
Questa tecnologia non riguarda la creazione di grafici esteticamente piacevoli, ma la trasformazione delle capacità decisionali in molteplici funzioni aziendali. Nella segmentazione dei clienti, invece di lottare con centinaia di variabili separatamente, il nostro approccio rivela raggruppamenti naturali di clienti basati su modelli comportamentali complessi che i metodi tradizionali mancherebbero. Questi segmenti emergenti spesso trascendono le categorizzazioni demografiche convenzionali, offrendo maggiore potere predittivo per iniziative di marketing e sviluppo prodotti.
Per i team di gestione prodotto, il nostro approccio di apprendimento delle varietà mappa come diverse caratteristiche e attributi si relazionano tra loro nell’intero portafoglio. Questa vista completa scopre reti complesse di preferenze dei clienti che non sarebbero visibili esaminando i prodotti individualmente. Il risultato è l’identificazione di opportunità di prodotto innovative che esistono in spazi attualmente non occupati nel panorama del mercato.
L’ottimizzazione della supply chain beneficia dall’identificazione di modelli nascosti nei dati logistici, rivelando relazioni non ovvie tra fattori operativi apparentemente non correlati. Visualizzando queste connessioni sulla varietà, le aziende possono identificare colli di bottiglia e inefficienze che rimangono invisibili nelle dashboard e nei report convenzionali.
Riduzione della Dimensionalità: Il Passo Finale di Visualizzazione
Come passo finale nella nostra pipeline, impieghiamo tecniche di riduzione della dimensionalità per creare visualizzazioni significative delle strutture complesse delle varietà che abbiamo scoperto. La nostra implementazione offre due opzioni potenti:
t-SNE (t-Distributed Stochastic Neighbor Embedding):
- Preserva la struttura locale con alta fedeltà
- Eccellente per identificare cluster compatti
- Rivela modelli a grana fine
UMAP (Uniform Manifold Approximation and Projection):
- Mantiene sia la struttura locale che globale
- Calcolo più rapido per grandi dataset
- Più stabile attraverso diversi parametri
Queste tecniche formano il livello finale di visualizzazione del nostro sistema, traducendo le complesse relazioni di distanza e le strutture delle varietà in rappresentazioni visive comprensibili che gli utenti aziendali possono esplorare e comprendere.
Visualizzazione: Rendere i Dati Tangibili
L’output della nostra pipeline di apprendimento delle varietà viene renderizzato attraverso mappe interattive Leaflet, creando una rappresentazione spaziale intuitiva del panorama dei tuoi dati. Questo sistema di visualizzazione include una sofisticata codifica dei colori basata su variabili categoriche o numeriche, permettendoti di identificare istantaneamente modelli attraverso molteplici dimensioni aziendali simultaneamente. Quando si lavora con dati segmentati per campi categorici come tipi di prodotto, segmenti di clienti o periodi temporali, il nostro sistema a griglia organizza questi blocchi in un layout coeso, abilitando sia l’esplorazione dettagliata all’interno delle categorie che l’analisi comparativa tra di esse.
La visualizzazione non mostra solo la riduzione della dimensionalità; mantiene le connessioni con tutte le metriche di distanza calcolate, gli spazi di embedding e le caratteristiche originali. Questo permette agli utenti di alternare tra diverse prospettive sulla stessa varietà sottostante, ottenendo una comprensione più completa della struttura dei dati. La codifica dei colori dei punti basata su diverse variabili illumina come vari fattori aziendali si relazionano ai modelli scoperti, mentre il filtraggio interattivo consente il test delle ipotesi e l’esplorazione di scenari in tempo reale.
Realizzazione del Valore Aziendale
L’impatto aziendale immediato deriva dalla trasformazione di una complessità travolgente in insight chiari e attuabili. I team di marketing possono raggiungere segmenti di clienti precedentemente invisibili con messaggi personalizzati. I team di prodotto possono identificare lacune nelle offerte attuali e opportunità di innovazione. Le operazioni possono individuare inefficienze e ottimizzare i flussi di lavoro basandosi su modelli appena visibili. I team esecutivi ottengono una vista olistica del panorama aziendale, consentendo una pianificazione strategica più efficace e un posizionamento competitivo.
La riduzione della dimensionalità non riguarda la semplificazione dei dati, ma l’amplificazione della comprensione. Trasformando la complessità in chiarezza attraverso sofisticate tecniche di apprendimento delle varietà, questo approccio consente alle aziende di vedere la foresta e gli alberi simultaneamente, creando connessioni che guidano il vantaggio competitivo in un ambiente aziendale sempre più ricco di dati.
Attraverso il nostro approccio tecnico completo, combinando apprendimento delle varietà basato sulle distanze, embedding di transformer, riduzione della dimensionalità t-SNE e UMAP, visualizzazioni interattive Leaflet, sistemi a griglia categorica e rilevamento degli outlier consapevole delle varietà, traduciamo la complessità dei tuoi dati in una narrativa chiara e attuabile che genera valore aziendale in ogni dipartimento.
Repository GitHub
https://github.com/Tailoredia/deepscope/tree/develop
Riferimenti
[1] Tenenbaum, J. B., de Silva, V., & Langford, J. C. (2000). A global geometric framework for nonlinear dimensionality reduction. Science, 290(5500), 2319-2323.
[2] Belkin, M., & Niyogi, P. (2003). Laplacian eigenmaps and spectral techniques for embedding and clustering. Advances in Neural Information Processing Systems, 14.
[3] Van Der Maaten, L., & Hinton, G. (2008). Visualizing data using t-SNE. Journal of Machine Learning Research, 9(Nov), 2579-2605.
[4] McInnes, L., Healy, J., & Melville, J. (2018). UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction. ArXiv e-prints.
[5] Liu, F. T., Ting, K. M., & Zhou, Z. H. (2008). Isolation forest. In 2008 Eighth IEEE International Conference on Data Mining (pp. 413-422).
